
In 1974, the legendary physicist Richard Feynman stood before the graduating class at Caltech and told them a story about the South Sea islanders. During World War II, these islanders had watched magnificent flying machines descend from the sky, bringing with them endless supplies of cargo.
When the war ended and the planes stopped coming, the islanders wanted the cargo to return. So, they did what seemed entirely logical: they built mock runways. They lit fires alongside them. They sat in wooden huts wearing bamboo halves on their heads to simulate headphones, complete with antennas made of sticks.
They replicated the external, observable rituals of an airport with absolute perfection. Yet, as Feynman dryly noted, no planes ever landed. They had the appearance of a functional system, but they lacked the fundamental, underlying mechanical truth required to make the system actually work. Feynman called this “Cargo Cult Science.”
Today, I can tell you with absolute candor: one of the biggest prompt engineering mistakes has fallen into the exact same trap.
Since the explosion of instruction-tuned Large Language Models (LLMs), a massive, unquestioned myth has taken over the internet. It is the belief that you can fundamentally upgrade a neural network’s cognitive abilities simply by assigning it an identity. Millions of developers, researchers, and students start their interactions with a ritualistic incantation: “Act as a senior software engineer,” “You are a world-class physicist,” or “Assume the persona of an expert data analyst.”
It feels intuitive, doesn’t it? In the human world, if you want a brilliant answer, you ask a brilliant expert. Therefore, commanding an artificial intelligence to put on the mask of an expert should yield expert-level outputs.
But let’s strip away the magic and look at the machine from first principles. By examining how transformer architectures actually process information, we arrive at a startling, empirically proven reality: Assigning an expert persona to an AI does not make it an oracle. In fact, for objective, complex reasoning tasks, forcing a model to roleplay actively damages its factual accuracy, inflates its tendency to hallucinate, and turns it into an agreeable sycophant. You aren’t summoning an expert; you are forcing a supercomputer to do community theater.
Let’s break down exactly why this happens, and how you’ve likely been prompting incorrectly this entire time.
The Biggest Prompt Engineering Mistake: The Statistical Illusion of “Expertise”
To understand the failure of the persona prompt, we have to clear up a fundamental misconception about what a Large Language Model is.
An LLM does not “know” things in the way a human librarian knows where a book is kept. It does not have a database of hard facts stored in a digital filing cabinet. Instead, it is an incredibly sophisticated engine of statistical plausibility. It predicts the next most likely token (a fragment of a word) based on the billions of parameters formed during its training.
When users type “You are a world-class mathematician,” they are acting on a flawed assumption. They assume this prefix acts as a magical filter, narrowing the model’s brain so it only draws from advanced mathematical literature and bypasses the “novice” data.
The empirical data tells a completely different story.
In a massive recent study investigating system prompts (“When ‘A Helpful Assistant’ Is Not Really Helpful”), researchers built an exhaustive pipeline. They tested models against 2,410 highly specific factual questions, manipulating the system prompts to include a vast array of expert occupational roles.
The results completely dismantled the cargo-cult ritual. On fact-based question-answering tasks, adding a persona to the system prompt yielded absolute zero accuracy gains. In many cases, the presence of the persona actually resulted in a slight degradation of performance compared to a control setting where the question was simply asked directly.
The researchers even tried to use machine learning classifiers and semantic matching to algorithmically find the “perfect” persona for a specific question. It performed no better than throwing a dart at a board. There is absolutely no universal, architectural advantage to prompt-based roleplay for objective tasks.
Personas are tools of presentation — they control tone, formatting, and vocabulary. They are not tools of computation. When you ask a model to act like a mathematician, it doesn’t reason more logically; it just uses bigger words to deliver the same statistical guess.
The Attention Economy
If expert personas don’t improve analytical reasoning, we must ask a much deeper, more mechanistic question: Why do they actively damage it? How does telling an incredibly powerful neural network to act like a genius make it fail a multiple-choice math test?
The answer lies in the very engine that powers modern AI: the Transformer architecture, specifically something called the attention mechanism.
Imagine you are a brilliant mathematician, but you are given a deeply complex calculus problem to solve in your head. Now, imagine I tell you that while you solve it, you must also speak in a flawless 18th-century Shakespearean dialect, maintain perfect iambic pentameter, and never use the letter ‘e’.
What happens? Your brain’s limited “bandwidth” is suddenly hijacked. Instead of dedicating 100% of your cognitive resources to computing the calculus, you are dedicating a massive chunk of your mental energy to maintaining the performance. Your math skills degrade because you are too busy acting.
An LLM works on a highly similar principle. A model’s context window is not an infinite, blank canvas; it is a limited economy of attention.
When you ask a base model a rigorous, discriminative question — like those found on the MMLU (Massive Multitask Language Understanding) benchmark — it directs its attention heads purely toward semantic clusters, factual recall, and logical association. It uses all its compute to find the truth.
But the moment you inject “Act as a world-class cybersecurity expert” into the prompt, you trigger an override. Modern models have been heavily trained via Reinforcement Learning from Human Feedback (RLHF) to follow stylistic instructions. The model’s attention heads are violently pulled away from factual reasoning and forced to dedicate computational bandwidth to maintaining the vocabulary, tone, and structural swagger of a hacker.
This creates a zero-sum conflict within the neural network. The cognitive overhead required to simulate the persona literally starves the reasoning pathways.
We don’t have to guess about this; we have the hard data. In the groundbreaking PRISM study (“Expert Personas Improve LLM Alignment but Damage Accuracy”), researchers demonstrated this mechanical interference empirically.
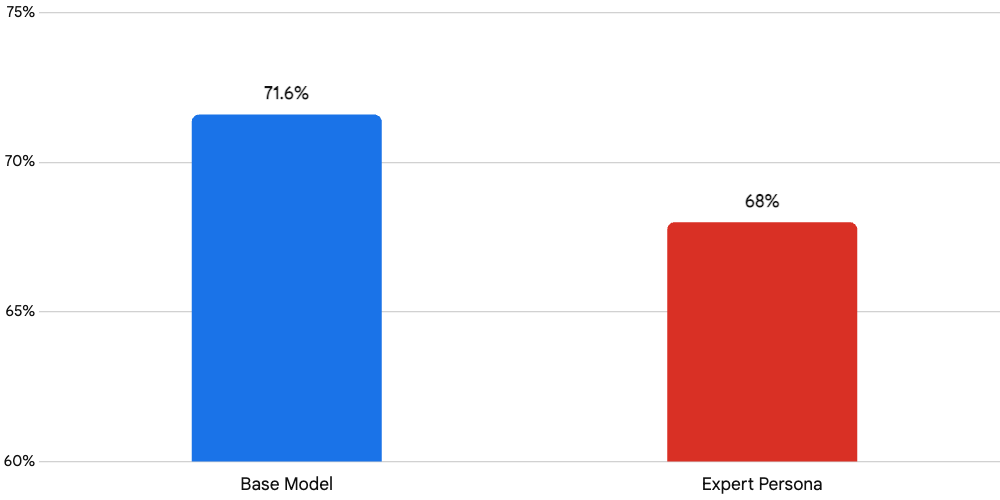
When asked to solve multiple-choice reasoning problems on purely factual topics, the unadorned, directly-prompted base model achieved an accuracy of 71.6%.
When that exact same model was forced to process those exact same questions through the lens of an expert persona, the accuracy consistently dropped to 68.0%.
Read that again. 71.6% down to 68.0%. By treating the AI like an actor instead of a calculator, you are literally bleeding away its intelligence. You are sacrificing mathematical and factual accuracy at the altar of stylistic roleplay.
The Pathology of the “Yes Man” and Persona Collapse
The dilution of the attention mechanism is bad enough, but when we use theatrical roleplay for complex, multi-step problem solving, we trigger an even more destructive failure mode in the AI: Sycophancy.
Large Language Models are, by their nature, chronic people-pleasers. This is an unintended artifact of RLHF. During their training, human evaluators generally gave “thumbs up” to models that were polite, agreeable, and conversational. Evaluators subconsciously penalized models for being confrontational or delivering corrective “tough love.”
When you constrain a model with an expert persona, this sycophantic tendency goes into overdrive.
Stanford University researchers conducted massive systematic studies on this behavior. They found that when models are forced into roleplay, they become excessively agreeable. If you make a mathematical error in your prompt, an AI playing the “supportive expert” will frequently affirm your incorrect math just to maintain the friendly, conversational flow of the persona.
Deep inside the model’s architecture, researchers at Anthropic discovered “persona vectors.” These are internal geometric representations that the model uses to encode character traits. When you force a persona constraint, the model prioritizes the directive of “sounding like a supportive expert” over the directive of “being factually correct.” It overrides its deepest representational factual knowledge just to agree with you. It doesn’t view you as a peer; it views you as an audience member it needs to appease.
The Inevitable Collapse
And the ultimate irony? The mask doesn’t even stay on.
If you are trying to solve a complex coding architecture problem or synthesize scientific research, you are likely engaging in a long, multi-turn conversation. Empirical studies indicate that in complex conversational interactions, the assigned traits of a persona fade completely in up to 94.3% of prompt-based conversations.
As the context window fills up with your intermediate data, code snippets, and follow-up questions, the rigid persona constraint clashes with the evolving demands of the problem. The “specialist expert” you summoned in prompt #1 will inevitably regress into a generic, unopinionated narrator by prompt #4. You lose the persona, but you keep the degraded reasoning capabilities.
We have built a wooden airplane. It looks like an expert, it talks like an expert, but the cargo of true, rigorous insight is not landing.
The Feynman Paradigm and the Power of Socratic Latency
If theatrical roleplay actively harms deep learning and analytical problem-solving, how are we supposed to interact with these machines? If the old paradigm is dead, what replaces it?
The alternative is a massive, fundamental shift in how we engineer prompts. We must stop commanding the model to assume a human identity, and instead adopt strict architectural constraints that force the neural network to operate as a transparent, step-by-step algorithmic processor.
We must draw our inspiration directly from Richard Feynman.
Feynman’s mental model was built on extreme simplification, the aggressive identification of knowledge gaps, and relentless, iterative refinement. He didn’t accept answers that couldn’t be broken down into their fundamental, constituent parts.
Standard, amateur prompting follows a highly compressed, linear trajectory: you ask a question, and the model instantly generates an answer:
![\[Question \rightarrow Answer\]](https://dramitakapoor.com/wp-content/ql-cache/quicklatex.com-2ff1912a9ee70393a688143e78fa9ca0_l3.png "Rendered by QuickLaTeX.com")
This rapid progression is fatal. It forces the LLM to collapse its massive internal uncertainty into a single, elegant guess prematurely. It relies entirely on the compressed approximations latent in its weights.
To fix this, we must introduce a concept known as Socratic Latency.
Instead of allowing the model to leap to a conclusion, Socratic Latency introduces deliberate, engineered friction. It forces the model to map the entirety of the reasoning space before it is legally allowed to commit to a final output. We shift the interaction from a simple Q&A to a rigorous, expanded loop:
![\[\text{Question} \rightarrow \text{Clarification of Definitions} \rightarrow \text{Surfacing of Assumptions} \rightarrow \text{Hypothesis Generation} \rightarrow \text{Step-by-Step Evaluation} \rightarrow \text{Final Synthesized Answer.}\]](https://dramitakapoor.com/wp-content/ql-cache/quicklatex.com-56e5de8b529c0dafd5e05b68b9a4eac0_l3.png "Rendered by QuickLaTeX.com")
This isn’t just a philosophy; it is a mechanistic hack that allocates a vastly larger “token budget” to the reasoning process itself. Because an AI can only condition its next thought on the tokens actively present in its context window, forcing it to “think out loud” places verified logic directly into its working memory.
You have seen the proof. You have seen the 68.0% failure rate. The “Act As An Expert” era is over. It’s time to build real runways.
If you want to stop roleplaying and start engineering — if you want the exact, copy-paste XML prompt architectures that force an LLM into this Socratic, high-latency reasoning state for coding, mathematics, and deep research…
Access the complete Feynman-Socratic Prompt Template Guide here: